作为一个刚接触智驾的小白,在阅读了一系列论文并且收集了很多信息之后,得出了这个结论。
这是上海交通大学和商汤科技一起完成的任务,并且已经可以部署到实际的车辆上面去了。
github链接:OpenDriveLab/UniAD: [CVPR 2023 Best Paper Award] Planning-oriented Autonomous Driving
arXiv链接:[2212.10156] Planning-oriented Autonomous Driving
以下是我的学习总结。
前置知识:Transformer模型
研究背景
为独立任务配置独立模块会产生错误累计
多任务框架会产生 negative transfer
现有端到端框架
3.1 直接预测轨迹不进行监督,不安全
3.2 感知并预测制定安全机动,更复杂一点但是缺乏对各种模块的考虑
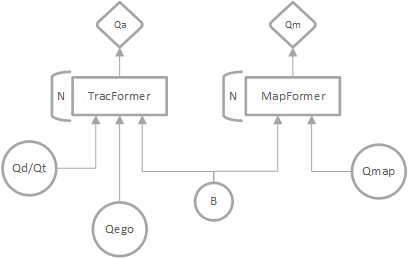
3.3 UniAD 以规划为导向,设计多个组件,以query为连接。
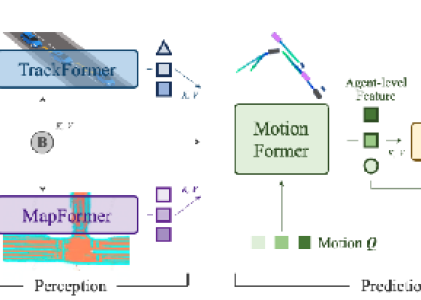
上述内容对应如下图:

UniAD模块说明

在 UniAD 框架中,每个模块(感知、预测、规划)通过特定的 Backbone 结构处理输入数据,为后续任务提供高效特征表示。
感知模块(Perception):
TrackFormer:检测和多目标跟踪,跨帧跟踪,自车查询。
MapFormer:使用query代表道路元素。
预测模块(Prediction):
MotionFormer:预测多模态未来轨迹,自车与其他agent交互。
OccFormer:预测未来的占用格栅地图,模拟场景的动态演变。
规划模块(Planning):
Planner:无需HDmap生成规划。
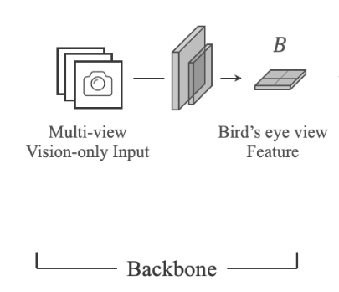
Backbone说明
功能:将多相机视角的图像数据转换为鸟瞰视角(BEV, Bird’s Eye View)特征,为模块间提供一致的环境表示。
模型:默认使用 BEVFormer ,但可以灵活替换为其他模型。
作用:获得BEV特征B,作为贯穿全局的信息,并使接下来的模块可以与其使用交叉注意力机制进行交互。
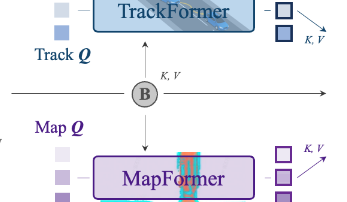
Perception 说明:
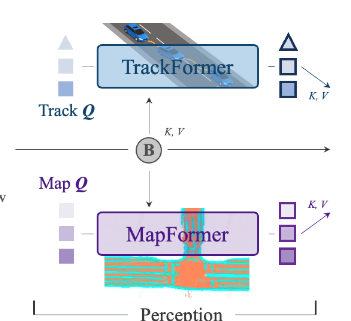
TrackFormer:
检测查询(Detection Queries):检测新出现的目标。
跟踪查询(Track Queries):跟踪已检测到的目标,确保帧间的一致性。
自车查询(Ego Query):专门用于捕捉自车状态,并与周围目标进行交互。
MapFormer:
道路查询(Map Queries):代表道路元素,捕捉其位置和结构。
MotionFormer说明
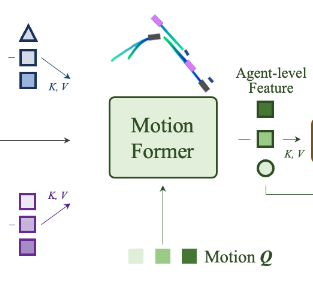
输入:Qa、Qm、B、Qctx
MotionFormer 模块有MotionQuery Q。包括Qpos和Qctx,Qctx=MLP(Qa,Qm,Qg)
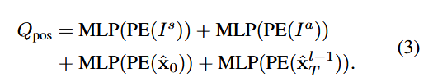
内部处理:
为perception层的输出,模型由 N 层组成,每层捕捉三种类型的交互信息:
主体-主体交互(agent-agent)
主体-地图交互(agent-map)
主体-目标点交互(agent-goal point)
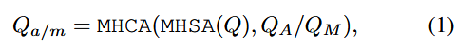
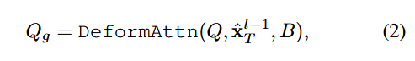
注意:在训练的时候,还会进行非线性优化,确保生成的轨迹具有物理可行性

输出:
Motion Q
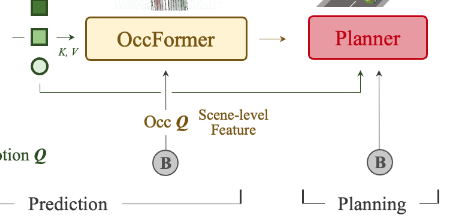
OccFormer说明:
输入:motion Q,BEV feature B,上一步密集特征 Ft -1,代理特征Gt,trackFormer输出Qa
G:Qx由motion Q池化得来,Pa是当前位置嵌入
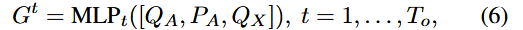
F t:在时间步t上的稠密场景特征,表示场景中所有像素的状态和特征。
内部处理:
场景密集特征和代理特征进行交互流程:
1. 下采样得到
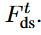
2. 通过注意力机制实现像素级别的Gt和
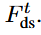
交互
智能体和场景之间的交互结果,并通过残差连接传递到下一层以进一步优化
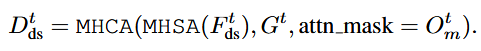
需要一个掩码,来实现每个像素只关注当前时间步t 中占据该像素的智能体。掩码特征

3. 上采样将预测和场景对齐
4.实例级别预测
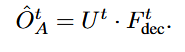
其中Fdec是上采样结果,Ut是占用特征,Ut=MLP(Mt)
Planer 说明:
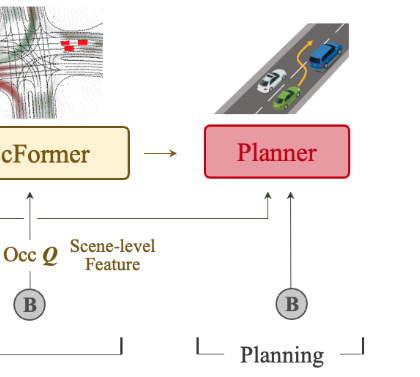
输入:自车查询 + 命令嵌入 + BEV 特征。
内部变化:规划查询与 BEV 特征交互,生成初始路径。使用牛顿法优化路径,避免障碍物碰撞。
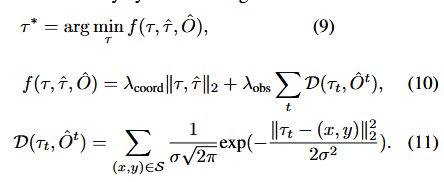
输出:最终优化路径 ,供自动驾驶车辆执行。
训练过程说明
输入:感知数据和运动轨迹数据。
内部变化:
两阶段训练:先单独训练感知模块,再进行端到端训练。
共享匹配机制:确保在不同模块(检测、跟踪、预测和规划)之间,每个智能体的身份都保持一致。
主要使用二分匹配算法、并且在TrackFormer中保存匹配关系,供后续模块使用。
输出:稳定且一致的模型,使 UniAD 能高效完成检测、预测和规划任务。
实验结果
使用nuScenes数据集。
在各个模块上都达到了SOTA。
并进行了消融实验
启发
我认为之所以能成为CVPR best paper,是因为这篇论文提出了一种可拓展易复现的框架,能够在任何任务将任何模块通过query整合在一起。