arXiv:[2206.00152] Human-AI Shared Control via Policy Dissection
github:https://metadriverse.github.io/policydissect
这篇论文是人和模型的share control,讲的是如何在训练好的模型中,无需训练就引入人类控制,实现方案是根据人类的指令直接控制这些神经元的激活值。
这个论文我阅读的很是吃力,因为其中涉及到了一些神经学知识、频率知识,我在做笔记的时候做的挺复杂的,但是作为分享感觉有点臃肿,我这里尽量简化并且抓重点来将。
在阅读之前要注意几个概念:
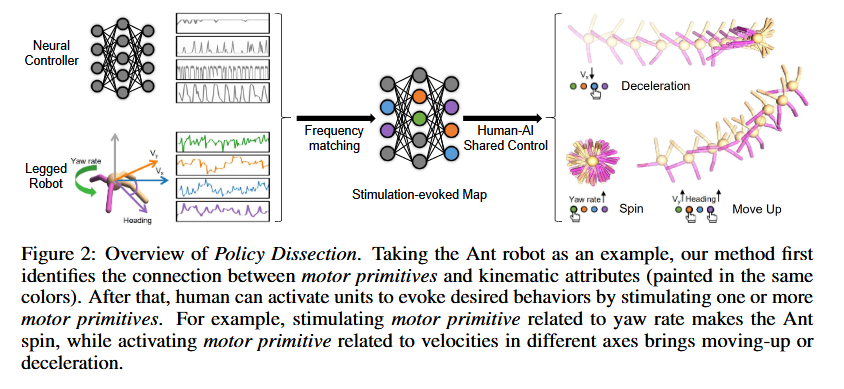
- Policy Dissection:策略解析,将学习到的神经控制器的中间表示与代理行为的运动学属性对齐。
- Motor primitives:运动原始单位,一个神经科学的概念,每个运动学属性的变化是通过激活特定的神经单元来实现的,每个运动原始单位与某一运动学属性(如高度、俯仰角等)密切相关。当我们激活这些运动原始单位时,机器人就能控制相应的运动学属性,进而完成预定的行为。
- stimulation-evoked map:刺激-响应映射或者刺激引发图,就是运动原始单位与行为之间的映射关系。
摘要
受神经科学研究灵长类动物运动皮层方法的启发,我们开发了一种简单而有效的基于频率的方法,称为 策略解析(Policy Dissection),将学习到的神经控制器的中间表示与代理行为的运动学属性对齐。在不修改神经控制器或重新训练模型的情况下,所提出的方法可以将给定的RL训练策略转换为人类可控的策略。
原文只进行了对RL的应用,并没有应用到其他网络结构。这也是它在结论中提到的方法缺点之一。
介绍
以前方法分析
现存模型的问题:
- 缺乏足够的泛化能力:缺乏在无模型环境中,基于学习的代理能够在未知系统动态下发现可行的策略,但在看不见的环境中会有问题,这阻碍了它们在现实世界的部署。
- 难解释性:仍然很难理解神经网络的内部机制和决策,尤其是在发生异常行为时。
第一点也就是一个zero-shot的能力,详见End-to-end Autonomous Driving: Challenges and Frontiers,这是一个端到端模型未来发展的趋势。
以前的解决方法:人在环,进行强制干预或者提供高级指令。在训练过程中,一个高级目标被作为策略的输入,但是这种方法需要对很多参数(reward、初始状态、目标动作等)进行额外的设计,并且也缺乏可解释性。
这就是导师让我看的那个论文里的一个方法,详见CarlaLeaderboard
方法提出
策略解析(policy Dissection):不需要对训练施加影响,也不需要重新训练。
- 首先剖析所学习策略的内部表示
- 与特定的运动学属性对齐
- 调节内部表示的激活并产生相应运动
背景启发:受到灵长类动物动作皮层神经研究的影响,即在运动皮层的不同区域施加电刺激可以引发有意义的身体运动。因此,可以构建刺激诱发图,以揭示诱发的身体运动与位于运动皮层不同区域的运动神经元之间的关系。
刺激诱发图:通过电刺激不同区域的运动皮层,研究人员能够建立一个刺激-运动映射,从而揭示 不同运动神经元和特定身体运动 之间的关系。
大概流程:
- 收集数据:首先,执行一个经过训练的强化学习策略,收集多个回合(episodes)中的所有单元活动时间序列 以及与 运动学和动力学相关的变化 。
- 匹配单元与运动学属性:对每个运动学属性(如位置、速度等),寻找与该属性变化最匹配的神经网络单元。这里的“匹配”是指单元活动时间序列与运动学属性变化之间的频率差异最小 。
- 识别运动原始单位(motor primitives):经过上述匹配后,识别出的单元被称为“运动原始单位”。这些运动原始单位的激活状态能够引起相应的运动学变化。
- 激活运动原始单位进行动作的控制
例子:对于一个模拟环境中的Gym-Ant,要实现“向上移动”这一行为,可以通过调整两个运动学属性(偏航角度的增加和竖直速度的增加)。通过激活相应的运动原始单位,就能引发所需的运动行为。
意义与实验
意义:使用基于 Policy Dissection 的 人机共享控制系统,实验在 未见过的新环境 中展示了出色的 泛化能力 和 zero-shot 任务转移
具体实验
- 自动驾驶任务:
- 在此任务中,基准代理在 轻度交通 条件下进行训练,并在包含 未见过的近乎意外场景 的新测试环境中进行评估。
- 与基准代理在新环境中的 低效表现 相比,人机共享控制系统 在该任务中表现出色,成功率为95% ,并且几乎没有额外的成本。更重要的是,该系统提供了 安全保障 ,确保了自动驾驶代理的安全性。
- 四足机器人步态任务:
- 在这个任务中,四足机器人仅通过 本体感知状态(proprioceptive state)来避免障碍物,即使它的主要任务是 向前移动。通过共享控制,机器人能够在环境中避开障碍,显示了 Policy Dissection 在运动控制中的潜力。
这个论文的实验设计感觉也比较有特点,实验这里只做个大概,具体的看之后的文章内容。
Policy Dissection Method 策略解析方法
本方法的主要特点有两个:
- 无需重训代理:可以在训练好的强化学习(RL)代理上执行,无需修改原始奖励、环境或策略架构。只需运行几个回合并记录神经活动和运动学变化,之后进行对齐以发现运动原始单位。
- 运动技能激发:通过激活特定的运动原始单位,即便代理没有接受过相关训练,也能引发复杂的运动技能。
例如,图1显示,即便只训练双足机器人在原始任务中向前移动,通过策略解析方法,也能引导机器人实现抬脚、蹲下或后空翻等动作。
监测神经活动和运动学属性
神经控制器:假设代理使用多层感知机(MLP),包含Z个单元和L个隐藏层,每层包含l个单元。每个时间步长t的输出为 \(z_t^{l,i}\)
运动学属性:假设有J个运动学属性,表示 \(S=\{s^j\}\) ,其中\(j = 1, \dots, J\)。每个属性随时间变化,\(s_t^j\)表示时间步长t的输出。
每个运动学属性与一个运动原始单位\(m^j\)相关联,能够影响该属性的变化。我们的目标是通过连接神经单元和运动学属性,发现这些运动原始单位。
例如,图3展示了在Ant 机器人上,如何通过追踪神经单元和运动学数据(如偏航速率、速度),记录神经单元和运动学属性的时间序列,为后续分析做准备。
将单元与运动学属性关联
执行策略:运行预训练的策略并记录神经单元的激活情况和运动学属性(如偏航速率、速度)。
频域转换:使用短时傅里叶变换(STFT)将神经活动和运动学属性的时间序列转换为频域,得到频谱图(SG)。
频率差异计算:比较神经单元和运动学属性的频谱图,计算频率差异。
选择匹配神经单元:通过最小化频率差异,选择与运动学属性变化最相关的神经单元作为运动原始单位。
建立关联:将选出的神经单元与相应的运动学属性关联起来,表示这些神经单元负责控制该属性的变化。
构建刺激引发映射
行为生成:机器人的行为通过控制特定的运动学属性(如高度、俯仰角和膝部力量)来实现。例如,改变这些属性可以使机器人完成后空翻等动作。
运动原始单位:每个运动学属性的变化通过激活特定神经单元(运动原始单位)实现。当激活这些原始单位时,机器人能够控制相应的属性,完成预定动作。
刺激引发图:通过将多个运动原始单位与行为的关系整理成图,展示不同运动原始单位如何协同作用完成某个行为。例如,后空翻可能需要激活与高度、俯仰角和膝部力量相关的多个运动原始单位。
行为调整:在实际操作中,可能会出现副作用。例如,激活膝部力量的运动原始单位可能会导致不希望的滚转运动。通过激活与滚转相关的运动原始单位,可以调整这一副作用。
通过刺激引发图引导代理
在此步骤中,确定唤醒行为所需的神经基元值。在时间步t,激活某个运动原始单位,相当于给动作施加了一个导数:$$s^j_{t_1} = s^j_{t_0} + \int_{t_0}^{t_1} f(v^j) \, dt$$。其中,\(v^j\)是运动原始单位的输出,\(f\)用于将其映射到运动属性。
新的目标是理解f(v)的特性,特别是它与v之间的关系,以便通过选择正值或负值放大或减少s_j。例如,激活与y轴运动相关的单元,并输出正值,可以让机器人向左移动,负值则使其向右移动。
运动原始单位与运动学属性的相关性分析
通过计算频谱相位差异来评估神经单元和运动学属性的相关性。首先,找到运动学属性的主频率:$$\omega^* = \arg \max_{\omega} \sum_d SG(d, \omega | s_j)$$。
在每个STFT窗口中,计算运动原始单位和运动学属性在主频率\(\omega^*\)处的相位差异。然后,对所有实验中的相位差异进行平均,得到相关系数$p^j$:
$$p^j = \frac{1}{D \cdot N} \sum_d \sum_N \left[ \Phi(\text{STFT}(d, \omega^* | m_j)) – \Phi(\text{STFT}(d, \omega^* | s_j)) \right]$$
其中,D是时间窗口数,$\Phi$为提取相位的函数。将$p^j$归一化得到相关系数$\rho_j$:
$$\rho_j = 1 – \frac{|2p^ j|}{\pi}$$
相关系数$\rho_j$表明是否通过改变$m_j$的输出值来放大或减少$s_j$。
最终,确定运动原始单位的输出值v^j:
$$v^j = c^j \cdot \rho^j$$
其中,c^j为幅度系数,影响v^j的大小,从而影响s_j的变化。可以通过观察行为表现或外部PID控制器自动调整c^j,使代理实现目标状态。
实验
概述
- 关系实验:自动驾驶任务:展示了Policy Dissection在自动驾驶任务中的应用,分析了学习动态并揭示了关键运动原始单位与策略学习的关系。
- 泛化能力:共享自主控制的创新应用:探讨了人类与AI共享控制在提高未见环境中的泛化能力方面的作用,并展示了如何通过人类干预帮助AI更好地适应。
- 任务转移:四足机器人实验:通过本体感知状态训练的四足机器人,展示了如何在少量人类协助下完成障碍物回避任务,表明机器人能够在没有完整环境信息的情况下通过共享控制转移到新任务。
- 定性试验:双足机器人Cassie示范:展示了Policy Dissection在双足机器人Cassie上的应用,机器人仅通过前进训练,借助人类指导成功完成复杂障碍环境(跑酷场景)的任务。
- 定量实验:目标引导控制实验:通过对Policy Dissection在目标跟踪任务中的应用进行研究,评估其与现有目标引导控制器在控制精度上的表现,探索目标引导控制的挑战。
实验设计
实验环境
- MetaDrive(自动驾驶任务):
- 目标:让智能体驾驶并到达目的地。
- 训练:在50个轻度交通环境中训练。
- 测试:在20个高交通密度和障碍物的环境中测试。
- Pybullet-A1(机器人行走任务):
- 目标:训练四足机器人在不平坦地形上行走。
- 训练:智能体依赖本体感知状态训练,另一个智能体则训练避障任务。
- 测试:机器人需要绕过随机散布的障碍物。
评估指标
- 自动驾驶任务:
- 成功率:评估智能体能否到达目标地点。
- 越界率:智能体是否因驶出道路而终止任务。
- 碰撞成本:与车辆、障碍物、建筑等碰撞的成本。
- 人类参与成本:量化人类在人类-AI共享控制中的参与度。
- 回报:在不同环境中的奖励、成本和人类参与的平均值。
- 机器人行走任务:
- 移动距离:机器人在特定方向上的位移,衡量任务完成情况。
- 奖励:与奖励值结合,评估机器人性能。
引入人类
- 输入设备:使用键盘进行所有人类-AI共享控制实验。
- 按键映射:每个键激活特定的运动原始单位,改变行为或激活期。
- 默认行为:某个键映射到默认行为,不激活运动原始单位。
- 人类参与:实验有5名不同实验者参与,所有参与者都签署知情同意书,并获得补偿。
Policy Dissection对学习动态的理解
使用PPO在MetaDrive环境中训练智能体后,通过Policy Dissection分析了智能体行为,发现两个关键运动原始单位:
- 原语1:与速度(Speed)相关
- 原语2:与侧向距离(Side Distance)相关
通过频率差异分析,训练过程中,智能体逐渐学会控制这些属性:
- 原语1的频率差异减小,表示更好地控制速度。
- 原语2的频率差异减小,表示更好地控制侧向距离。
这些变化与成功率、越界率等学习进度指标强相关,表明运动原始单位对智能体学习进展起着关键作用。
人类-AI共享控制提高测试时的泛化能力
通过使用Policy Dissection识别的运动原始单位,我们实现了人类-AI共享控制,提高智能体在未见环境中的表现。流程如下:
- 构建刺激-响应映射:根据运动原始单位的激活值,引导运动属性(如速度、侧向距离等)。
- 与SAC和PPO合作:在SAC和PPO智能体的测试环境中应用共享控制,并邀请人类参与。
- 人类参与:在测试环境中,人类通过调整运动原始单位的激活值,帮助智能体完成精细操控任务。
- 评估性能:实验结果显示,人类的参与显著提高了智能体在未见环境中的成功率和安全性,尤其在需要精细控制的任务中表现更好。
在人类-AI共享控制下,测试环境中性能和安全性的提升。H表示“人类”。Hn和H∗表示两种接管方法。
Hn要求人类在整个接管期间提供转向和油门控制,而H∗仅在接管开始时要求激活运动原始单位。
人类-AI共享控制促进任务转移
测试时的泛化能力:这指的是通过使用刺激-响应映射(stimulation-evoked map)方法,强化学习(RL)代理不仅能在已知环境中表现出色,还能更好地适应新环境中的变化,特别是在面对不同的任务时,能够借助人的参与完成任务。
四足机器人和“无感知”策略:
- 四足机器人使用端到端控制的强化学习来在不平坦的地形上行走。“无感知”策略指的是机器人只能基于自身的感知(如关节角度等本体感知信息)做决策,缺乏对周围环境的感知,因此无法自主避开障碍物。
- 在Statew/oH方法中,在无感知的策略下,机器人没有视觉信息的帮助,仅依靠本体感知进行控制。
- H*加入了策略剖析
- State+Vision方法:直接在测试环境中训练一个包含视觉输入的运动控制策略,使机器人能够实时感知环境并自主避开障碍物。
定性实验:双足Cassie跑酷示范
在Cassie双足机器人上,通过Policy Dissection发现了多种运动技能,这些技能可以通过人类指导触发,帮助机器人解决复杂的跑酷环境任务。训练目标仅为前进,但通过运动原始单位的激活,机器人成功完成了具有挑战性的跑酷场景。
控制精度实验
我们在IsaacGym中对ANYmal-C机器人进行了目标引导控制实验。训练后的机器人使用PID控制器跟踪目标偏航角。通过Policy Dissection,我们识别出与偏航角相关的运动原始单位,并通过激活这些原语进行控制。结果表明,基于运动原始单位的控制精度与目标控制方法相当,证明了Policy Dissection在控制精度上的有效性。
结论
提出的方法已经比较清楚了。主要说一下缺陷:
- 只在以状态向量为输入的连续控制任务中评估这种方法,更多的任务和网络结构(类似离散任务和cnn网络)需要进一步评估。
- 在真实世界上部署时,安全性无法保证。
- 自动驾驶任务中,对人的安全性无法保证,并且人和AI无法良好的配合存在潜在的风险。