这个文章是nuplan上榜论文,创新点在于将agent之间的交互和规划结合,基于transformer和博弈论。
也是现在plan领域论文中常用的baseline。
ArXiv:https://arxiv.org/abs/2303.05760
github:https://mczhi.github.io/GameFormer/
摘要
本文关注复杂交通环境中自动驾驶车辆与其他交通参与者之间的交互行为,并且可以输出规划路径。提出了一种基于层次博弈论的交互预测模型—— GameFormer ,该模型结合了Transformer架构与多层次博弈推理机制,以高效捕捉交通场景中代理间的动态交互。
具体而言,GameFormer通过解码器模拟场景元素之间的关系,并采用分层编码器架构,使得每层编码器都能共享来自上层的环境信息。该模型在Waymo交互预测任务中实现了最新的性能,并在nuPlan数据集上排名第三。
1. 引言
背景:自动驾驶系统需要准确预测周围交通参与者的行为,以作出有效决策。然而,由于交通环境的高度复杂性,这一任务极具挑战性。现有的深度学习模型在利用历史轨迹预测代理行为方面取得了进展,但无法有效模拟多代理间的相互作用。
意义:为了提高自动驾驶决策的交互性与灵活性,本研究提出一种联合预测与规划的框架,采用层次博弈论来模拟多个智能体间的相互推理,并提升决策质量。
2. 相关工作
2.1 自动驾驶中的行为预测
往期工作用LSTM编码过去状态,用CNN处理格栅图像,GNN处理代理之间的交互。
但是Transformer出现之后,得到了广泛应用,如Scene-Transformer、WayFormer,但是很多现有方法关注的是编码器,很少有关注解码器的。
关于如何将预测模型用于规划任务,很多工作都集中在 多智能体联合动作预测框架 上,问题在于他们经常忽略了自动驾驶汽车的动作,使其不适合下游工作。为了解决这个问题,将AV规划信息集成到预测过程,但是仍是单向交互,忽略了互相的影响。
此论文 迭代交互建模共同预测周围代理的未来轨迹 ,并促进AV的规划。
2.2 从决策中学习
自动驾驶中的动作预测通常依赖模仿学习或强化学习,但这些方法缺乏鲁棒性和可解释性。
本文通过增强预测模型能力,以改进交互式决策,并通过博弈论实现多代理间的有效推理与规划。
3. GameFormer模型
3.1 博弈论框架
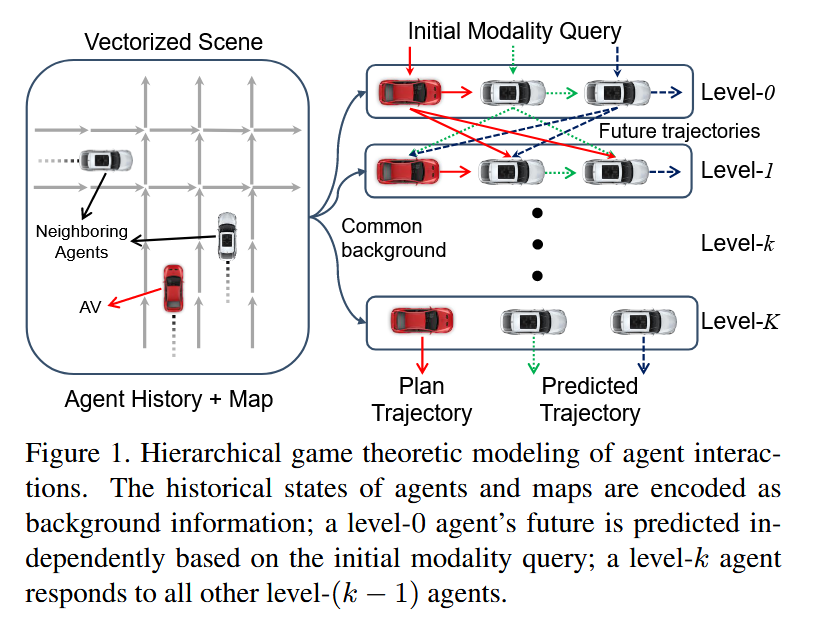
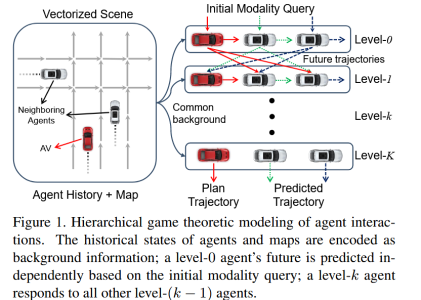
通过层次博弈论建模智能体间的交互,每一层的策略更新都考虑来自上层的代理预测。每个智能体的轨迹预测采用高斯混合模型(GMM),并基于过去轨迹与当前策略进行推理。
对场景内所有的agent进行建模,并用多模态轨迹的概率分布作为策略,每一层都利用上层的策略进行自身的策略更新,即损失函数表示的是智能体i在k层的策略与除了i之外的智能体在k-1层策略的损失。
3.2 场景编码
3.2.1 输入表示
主要有两个数据,代理的历史状态信息
和局部矢量化地图折线
对于每个agent来说Nm是附近需要关注的地图元素,Np是地图元素包含的waypoints,dp是其属性。
3.2.2 agent历史编码
使用LSTM网络对历史状态Sp进行编码,得到一个张量 ,包含所有代理的过去特征,D是隐藏层维度。
3.2.3 矢量地图编码
用MLP进行编码,输出是$M_p \in \mathbb{R}^{N\times N_m \times N_p \times D}$
然后,我们将同一地图元素中的waypoint进行分组,并使用最大池来聚合它们的特征,从而减少地图标记的数量。
最终的地图张量为 $$M_r \in \mathbb{R}^{N\times N_{mr} \times D}$$,Nmr代表聚合地图元素的数量
3.2.4 Relation Encoding
将智能体的特征与其对应的局部地图特征拼接,创建每个智能体的智能体场景上下文张量 $$C_i = [A_p, M_{p_i}] \in \mathbb{R}^{(N+N_{mr}) \times D$$ 。
接着,我们使用一个具有E 层的 Transformer 编码器来捕捉每个智能体上下文张量Ci 中所有场景元素之间的关系。
该 Transformer 编码器应用于所有智能体,生成一个最终的场景上下文编码 $$C_s \in \mathbb{R}^{N \times (N + N_{mr}) \times D}$$,该编码表示了后续解码器网络的共同环境背景输入。
3.3 未来轨迹解码与推理
- 模态嵌入
- Level0层的编码
- 交互解码
3.4 学习过程
通过模仿损失和交互损失对智能体的行为进行约束,确保模型不仅能准确预测个体行为,还能有效避免与其他智能体的碰撞。此外,引入排斥势场机制来增强智能体间的安全性。
4. 实验
4.1 实验设计
4.1.1 数据集
本文设置了两个不同的模型变体用于不同的评估任务:
- **预测导向模型** :该模型使用Waymo开放运动数据集(WOMD)进行训练,任务是预测两名互动代理的联合轨迹,预测时间为8秒。
- **规划导向模型**:该模型用于规划任务,使用WOMD数据集的互动场景和nuPlan数据集进行训练和测试。
4.1.2 预测导向模型
- 该模型基于WOMD的互动预测任务,预测两名互动代理在未来8秒的联合轨迹。
- 训练过程中,场景中的其他邻近代理作为背景信息,仅预测两名标注的互动代理的联合轨迹。
- 模型有两种设置:
– **联合预测设置**:预测6条联合轨迹。
– **边缘预测设置**:为每个代理预测64条轨迹,使用EM方法进行聚合,最终选择6条联合轨迹进行预测。
4.1.3 规划导向模型
- 该模型用于规划任务,考虑到周围多个邻近代理,预测其未来轨迹。模型在WOMD和nuPlan数据集上进行训练和测试。
- 在WOMD数据集中,随机选择10000个20秒的场景用于训练和验证,并在400个9秒的动态互动场景中评估模型性能。评估包括开放环和闭环设置:
– **开放环测试**:使用基于距离的误差指标进行评估。
– **闭环测试**:使用更接近实际驾驶的指标,如成功率、路径进展、纵向加速度、偏差等。
在nuPlan数据集上,评估模型在三个任务中的表现:开放环规划、闭环非反应性代理规划、以及闭环反应性代理规划,并根据一套综合指标进行评分。
4.2 主要结果
4.2.1 交互预测
4.2.2 开环规划
解码器数量的影响